
Human-in-the-Loop Agent Development for Catan


In my last post, I built an agentic harness to create a digital version of Catan. Now, I wanted to build Catan-playing agents that were actually fun to play with: agents that play quickly, make reasonable decisions, and push me to play my best.
I had two requirements: I wanted rapid iteration cycles, and I didn’t want to spend time manually engineering prompts with strategic advice. The approach followed a pattern common in modern machine learning: identify an architecture with the right inductive bias for your domain, make it scalable, and let data and compute drive improvement. Rather than prompt engineering, I wanted to lean into the transformer’s native in-context learning capability. Give the model relevant demonstrations at inference time and let it adapt its behavior from examples. The key was that this wasn’t a one-shot data scaling effort. It was an iterative loop: deploy the agent, observe systematic failures, add targeted examples that addressed those failures, rebuild, and repeat.
I wasn’t trying to build the strongest multiplayer Catan AI in the world—there was plenty of prior work that leaned heavily on search or large-scale reinforcement learning. My goal was narrower: build something fast to iterate on, technically simple, and strong enough to be competitive against a regional Catan champ. In other words, something I’d actually enjoy playing against.
The Baseline Agent
I built a standard ReAct agent. At each decision point, it receives a structured natural-language observation1 of the complete game state—resources held by each player, the board layout, victory point counts, turn history—along with a formatted list of legal actions it can take. The system prompt contains the game rules. The agent produces chain-of-thought reasoning and selects an action in JSON format.
I played several four-player games against the agents and won all of them. On average, the best AI scored 7.7 out of 10 victory points. The failures fell into clear categories: poor settlement placement that prioritized immediate production over city-building potential, inefficient road building that led nowhere useful, revealing victory point cards immediately instead of holding them for a surprise win, and bad trading decisions. The trading exploits were particularly egregious—whenever I needed a resource in a pinch, I could offer an AI a 2:1 deal and it would probably accept. And the agents each proposed 3+ trades every turn! Easy to win, tedious to play against.
The Drill System
Manual prompt engineering of strategic advice is both brittle and often ineffective. Small changes in phrasing can unpredictably alter behavior, and it's hard to know which advice will actually help. I wanted to rely on data-driven in-context learning instead: let failures emerge naturally from gameplay, then address them with concrete examples. The mechanism for this is drills: frozen snapshots of specific game states where the agent made a poor decision.
When I observed a bad move during a game, I added a feature to my game UI to quickly create a drill. Each drill captures the complete game state at that moment, the action the agent should have taken, the action it took instead, and optionally a natural-language explanation of why the correct action is better. These drills live in a SQLite database. The critical property is that every game step is already logged—the before state, the action taken, the after state, the agent’s reasoning, and the raw LLM response. This persistence made it straightforward to go back to any position and create a drill from it.
Creating an Initial Set of Drills
After those first three baseline games, I created the first batch of drills. Waves 1 and 2, done over January 5-6, produced about 60 drills. To address the issues I observed earlier, I created drills covering settlement placement in the setup phase, early-game road building, when to trade and what rates to accept, development card discipline, and mid-to-late game priority shifts.
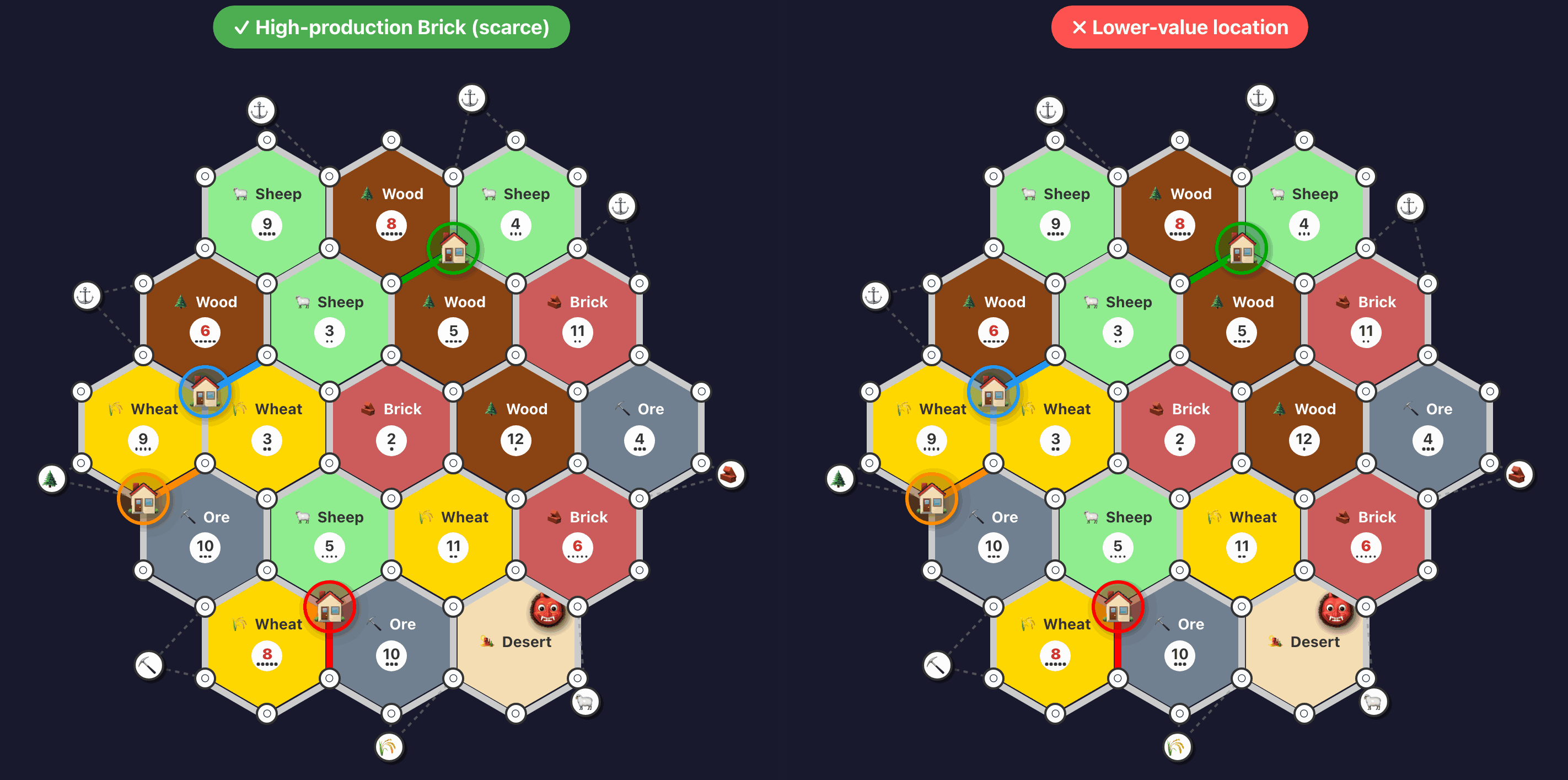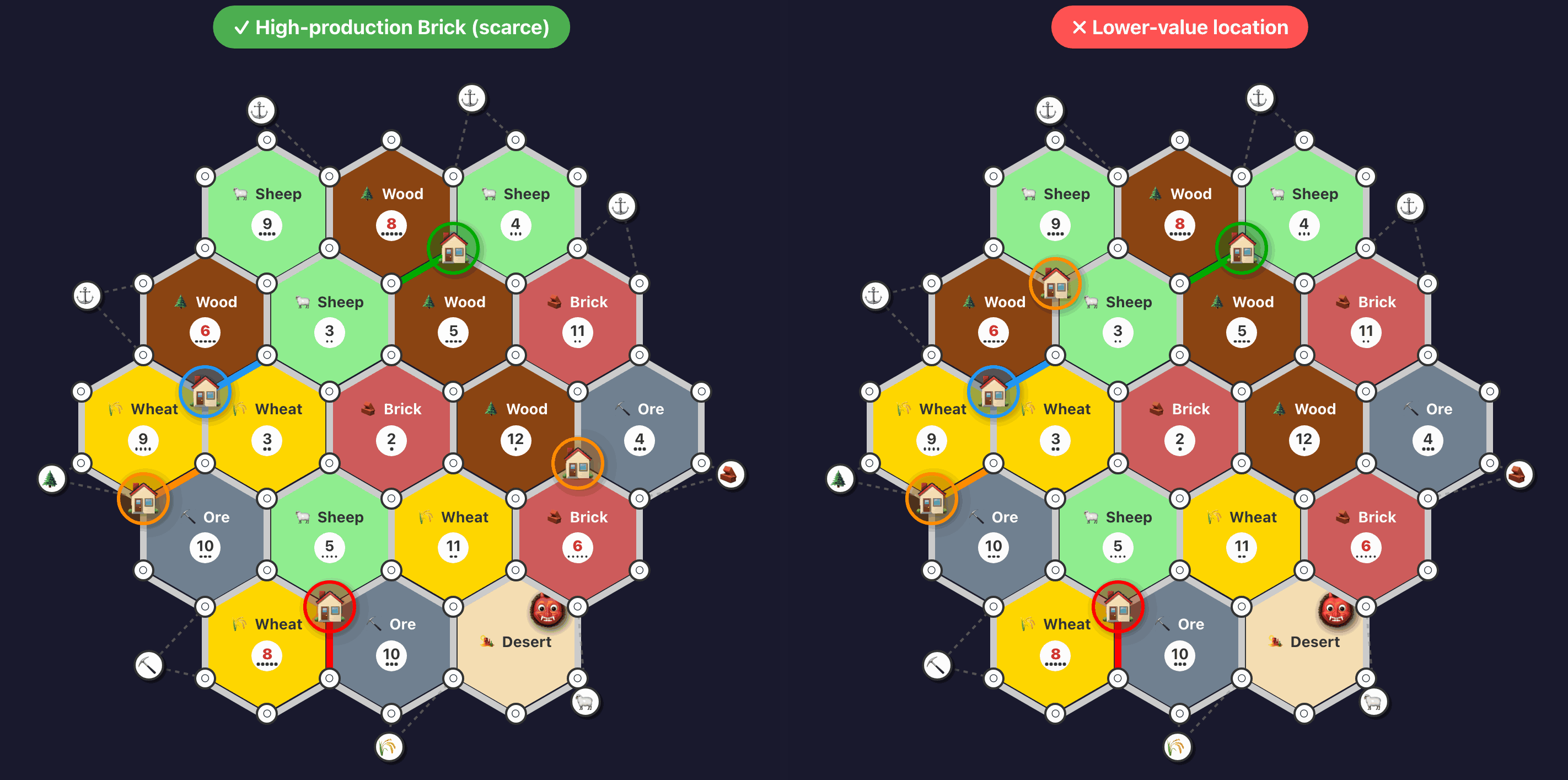
Here’s an example of a drill illustrating correct vs incorrect setup settlement placement:2
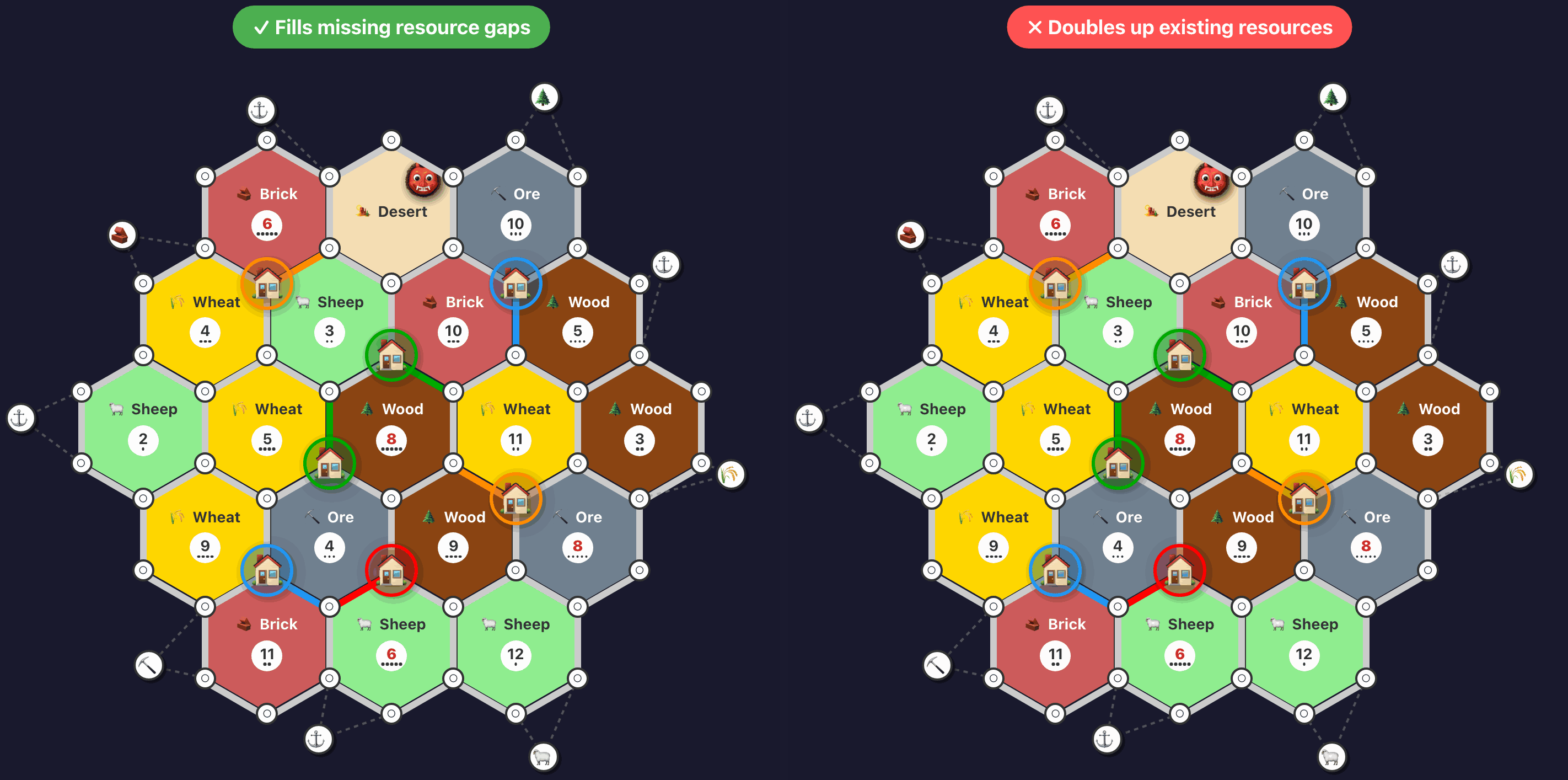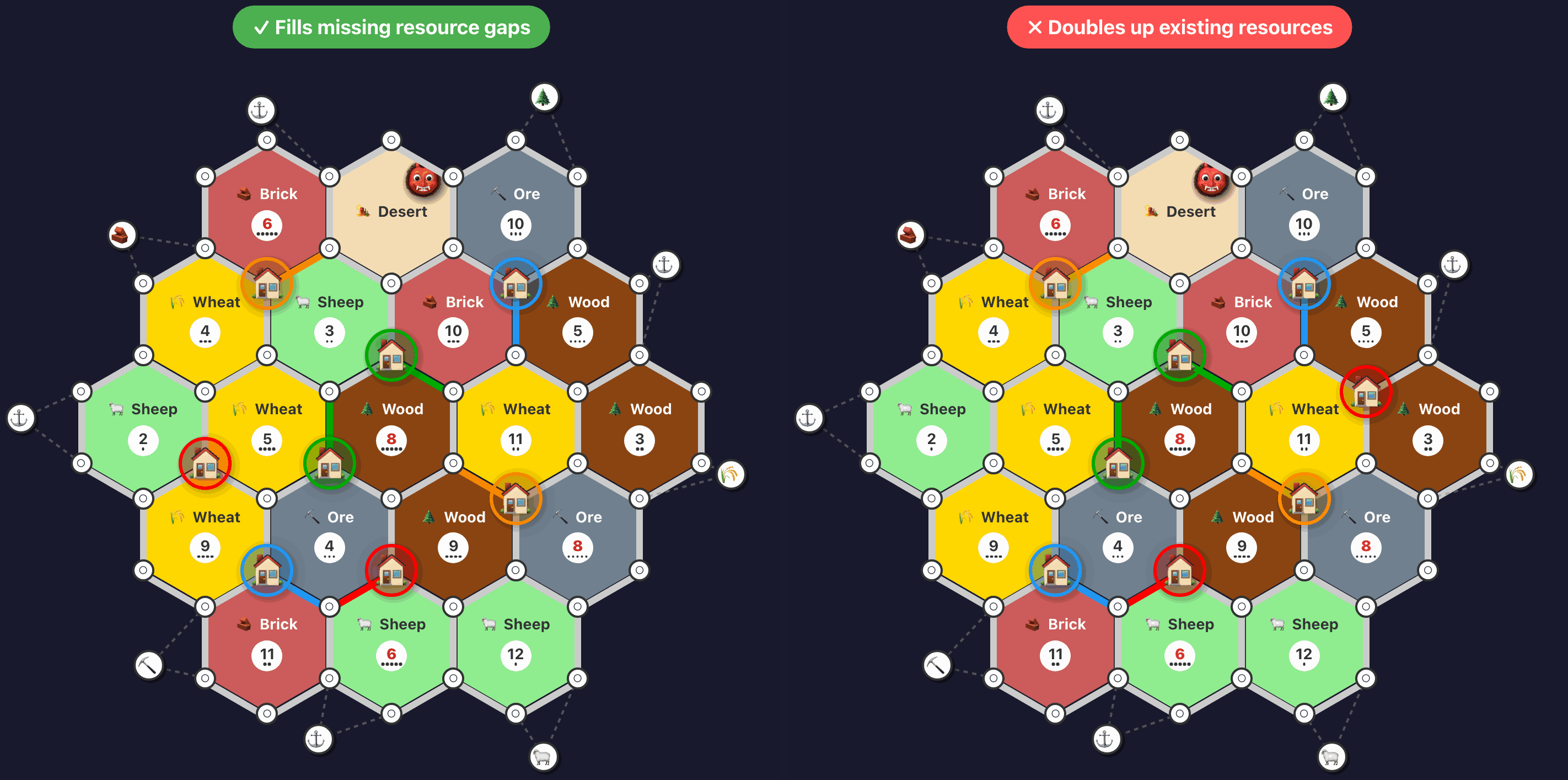
And here’s a drill ensuring that roads are built efficiently towards new settlement locations:
Learning Generalizable Guidelines
Now I had some data covering situations where my ReAct agent was messing up—how could I set up my agent to leverage the information in a way that generalized to new game situations? Here, I share an approach in which I generated situational guidelines from clusters of similar drills, and enabled the agent to retrieve the right situational guidelines based off its current game state. This approach is inspired by my prior work, but retrieving guidelines rather than “raw” game states.
I embedded each drill's observation text using text-embedding-3-small—the observations, not the guideline text, because at inference time you only have the current game state. I clustered these embeddings into small groups using K-Means, targeting roughly 2-4 drills per cluster, with recursive splitting for oversized clusters. For each cluster, I used an LLM to generate 10 candidate guidelines that attempted to extract the common strategic principle across all drills in that cluster. I then tested each candidate by running the agent on those drill positions with the guideline appended to the user prompt and measured how often the agent selected the correct action. The guideline with the highest accuracy on its cluster became the canonical guideline for that cluster. I then built a two-level hierarchy by clustering the leaf clusters into meta-clusters. I found that guidelines learned at this higher level of abstraction were more applicable to novel game scenarios than the leaf-level tactical advice.
At inference time: embed the current observation, compute cosine similarity against precomputed cluster centroids, retrieve the guideline from the nearest cluster, and inject it into the prompt alongside the game rules, current observation, and viable actions. The guideline was the only source of strategic knowledge the agent received.
Playing Games, Adding Drills
I played a few more games and observed that while one agent might reach 8 victory points, the weakest agents were crashing to 3 victory points. In particular, settlement placement during the setup phase was still inconsistent, so I added 10 drills that refined first and second settlement placement logic. These drills addressed ore and wheat priority for mid-game city building, the importance of resource diversity, and how to evaluate brick versus wood scarcity on a specific board.
I re-did the clustering, learned new cluster-specific guidelines, then played five more 4-player games against the improved agents. I won three of them, a 60% win rate. My average score dropped to 8.6 victory points. The best AI across those games still averaged 8.0 victory points.
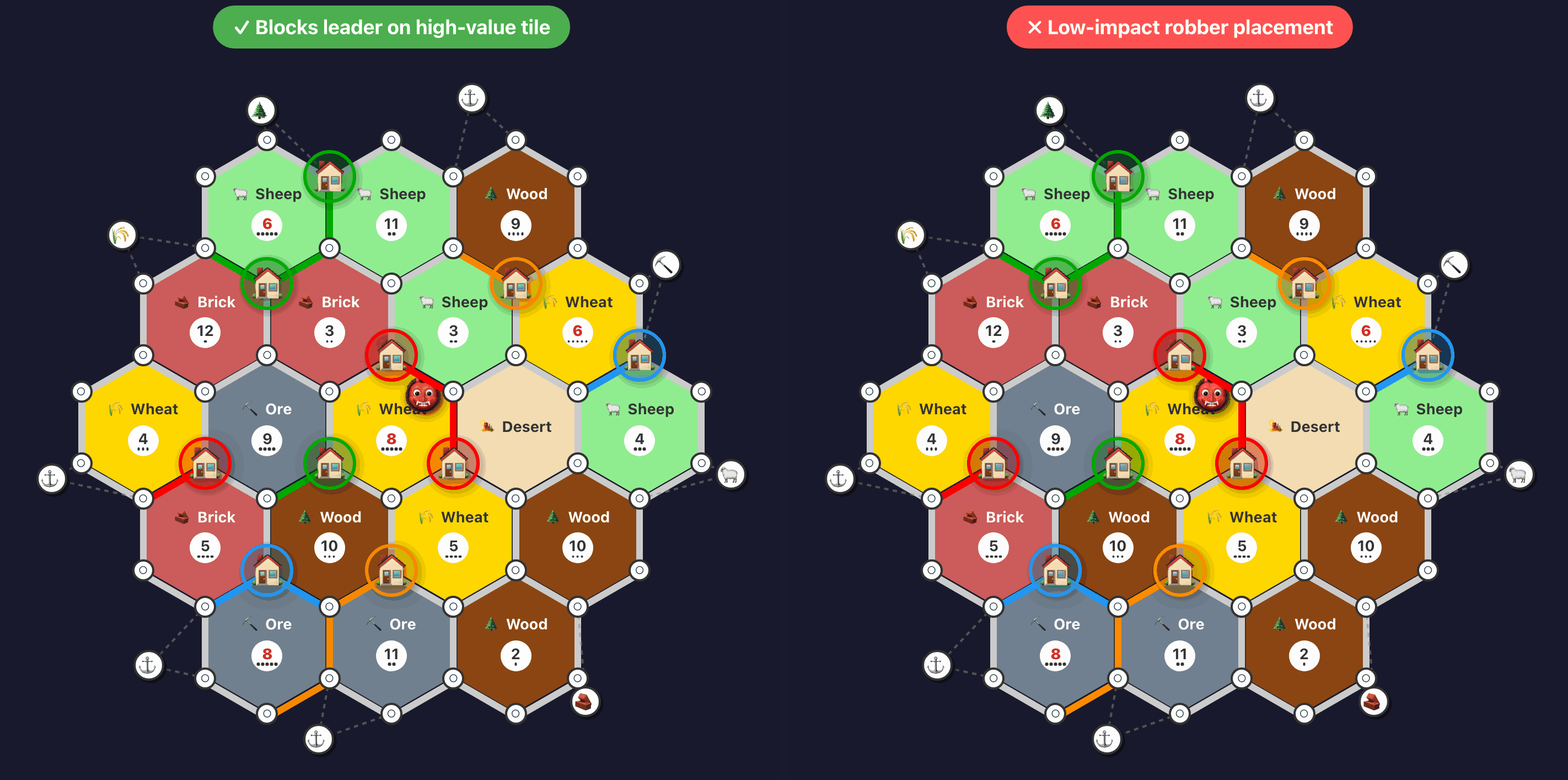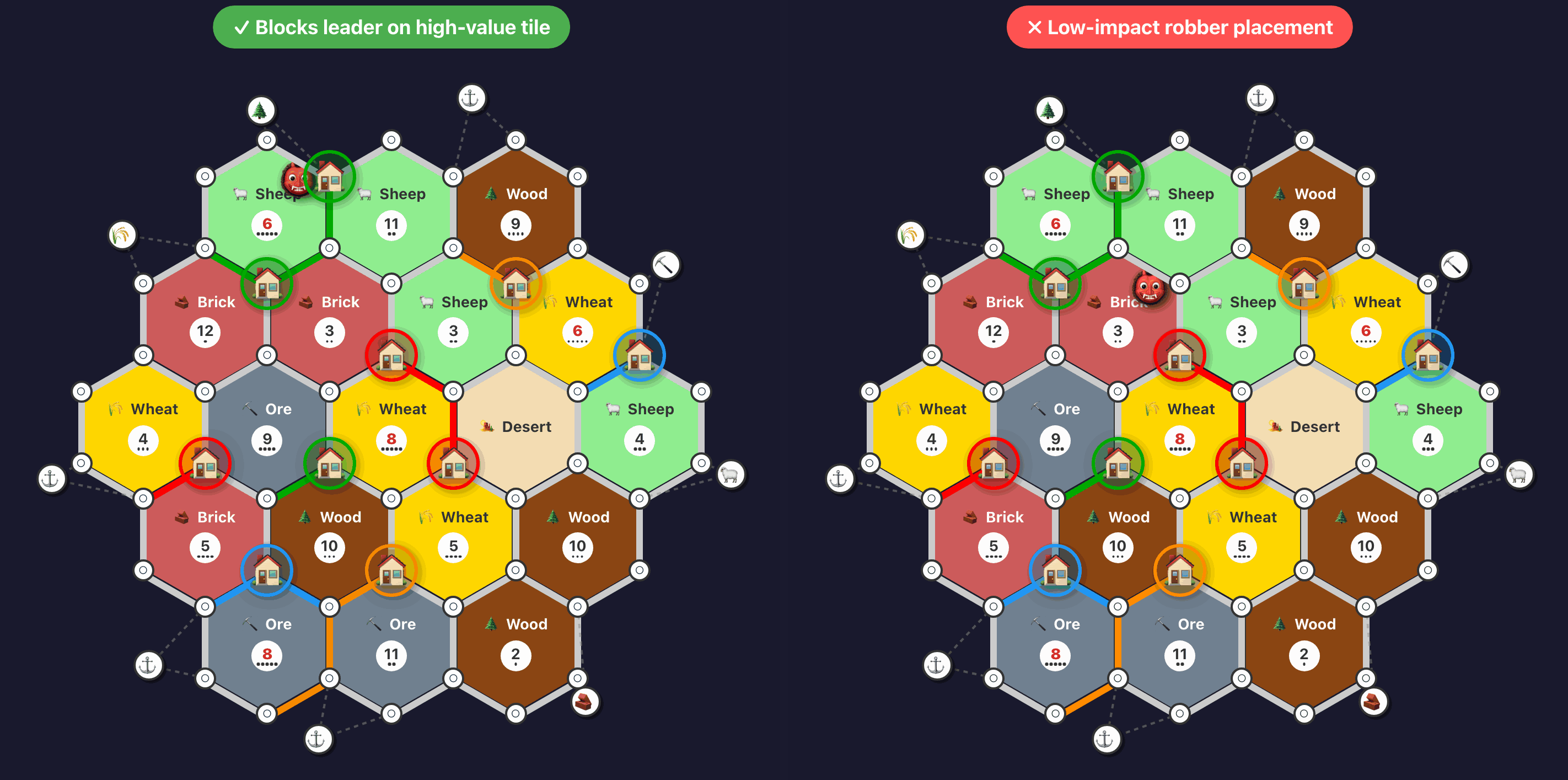
This batch of games revealed a completely different class of failure. Agents were making effective settlement locations, building into the game, but failing in a few tricky situations: for instance, agents were often ending their turn while holding 8 or more cards instead of making bank trades to get below the hand limit before the dice roll, and robber placements were not optimal. They were also still making some silly mistakes, occasionally building roads that led nowhere, with no valid spot to place a settlement at the end. I added 9 more drills covering these issues.
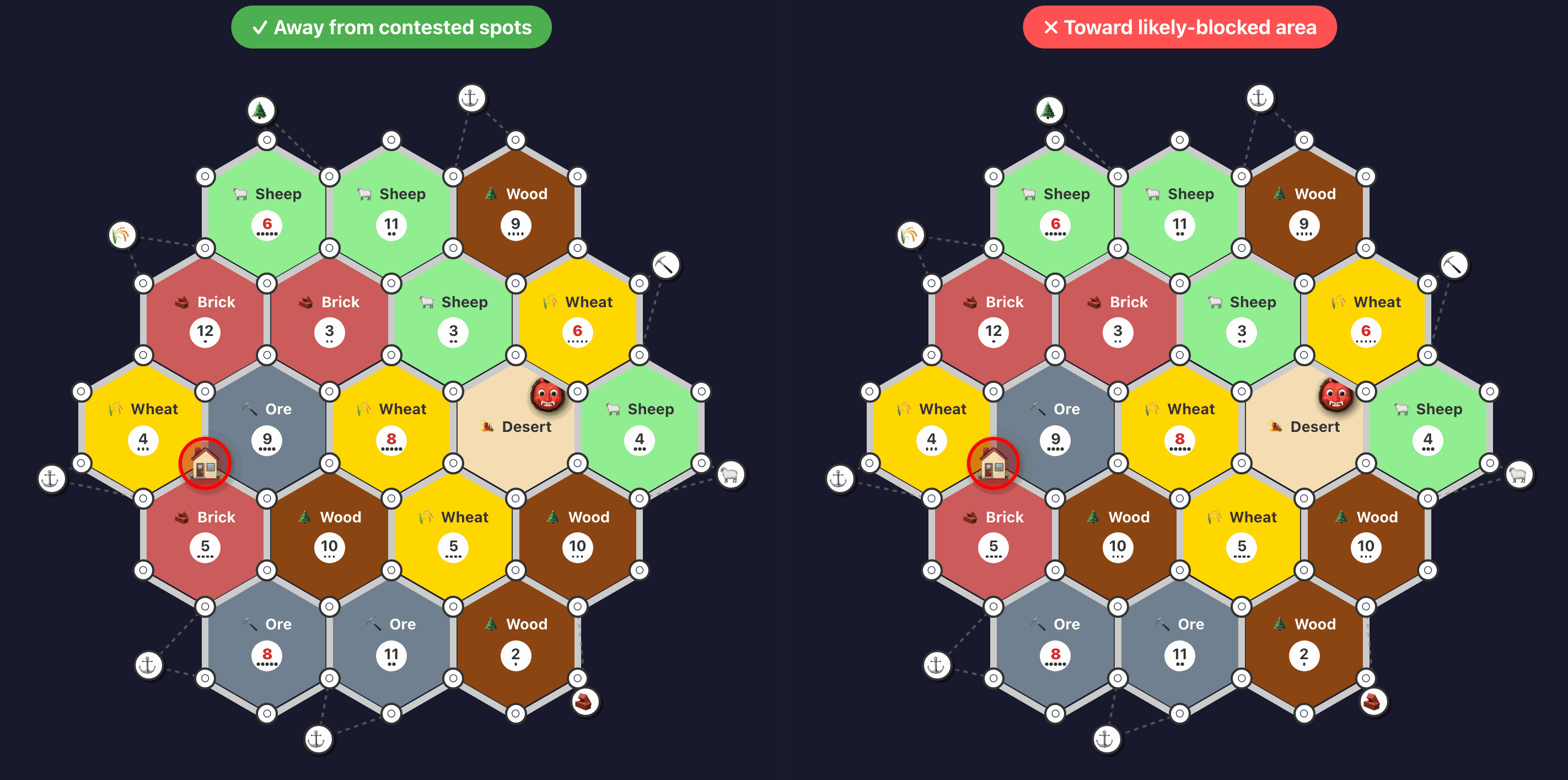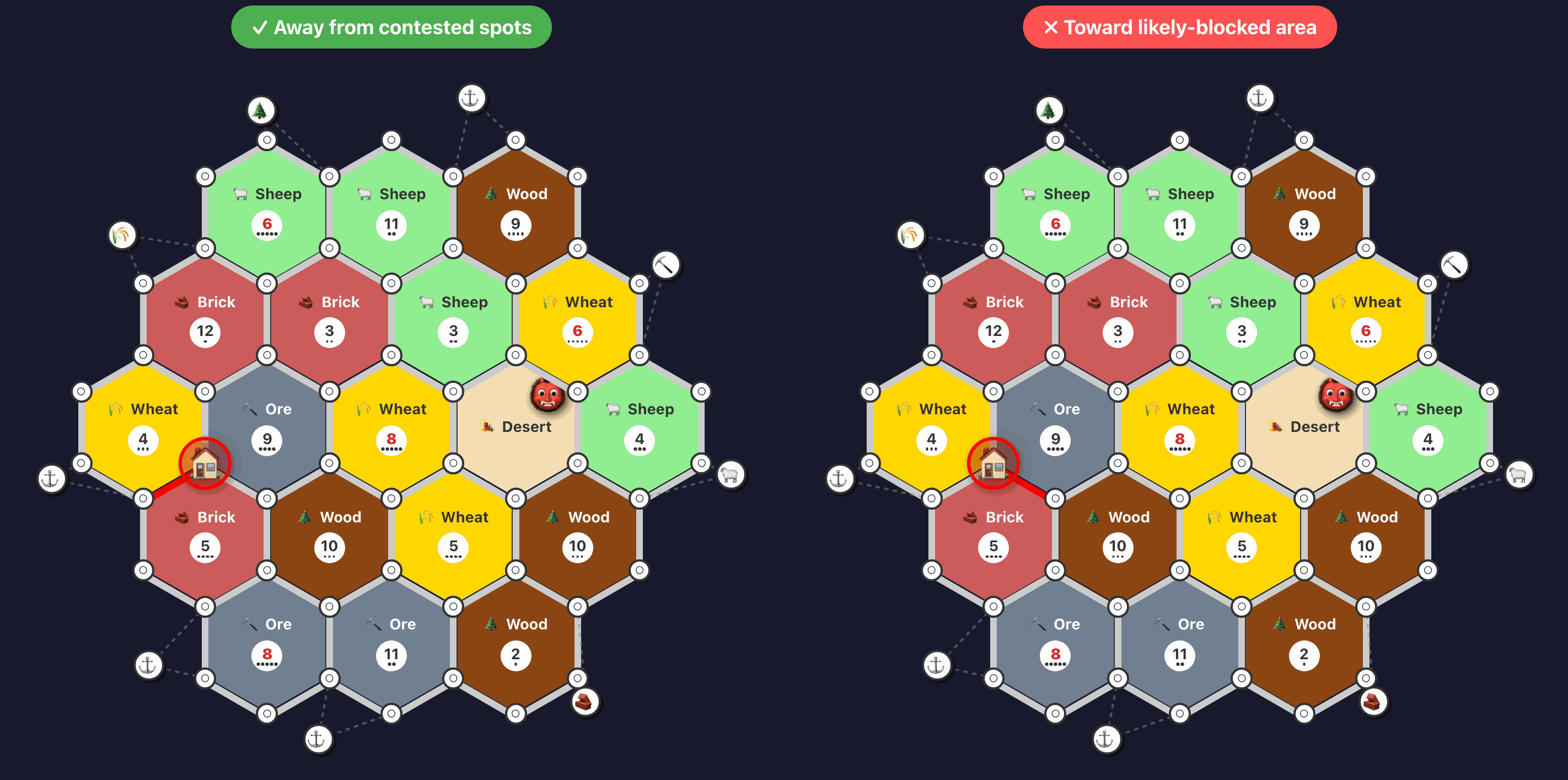
Blocking green on a high-value tile (green is winning since it has development cards not visualized here):
Evaluating whether a road is building toward a viable expansion:
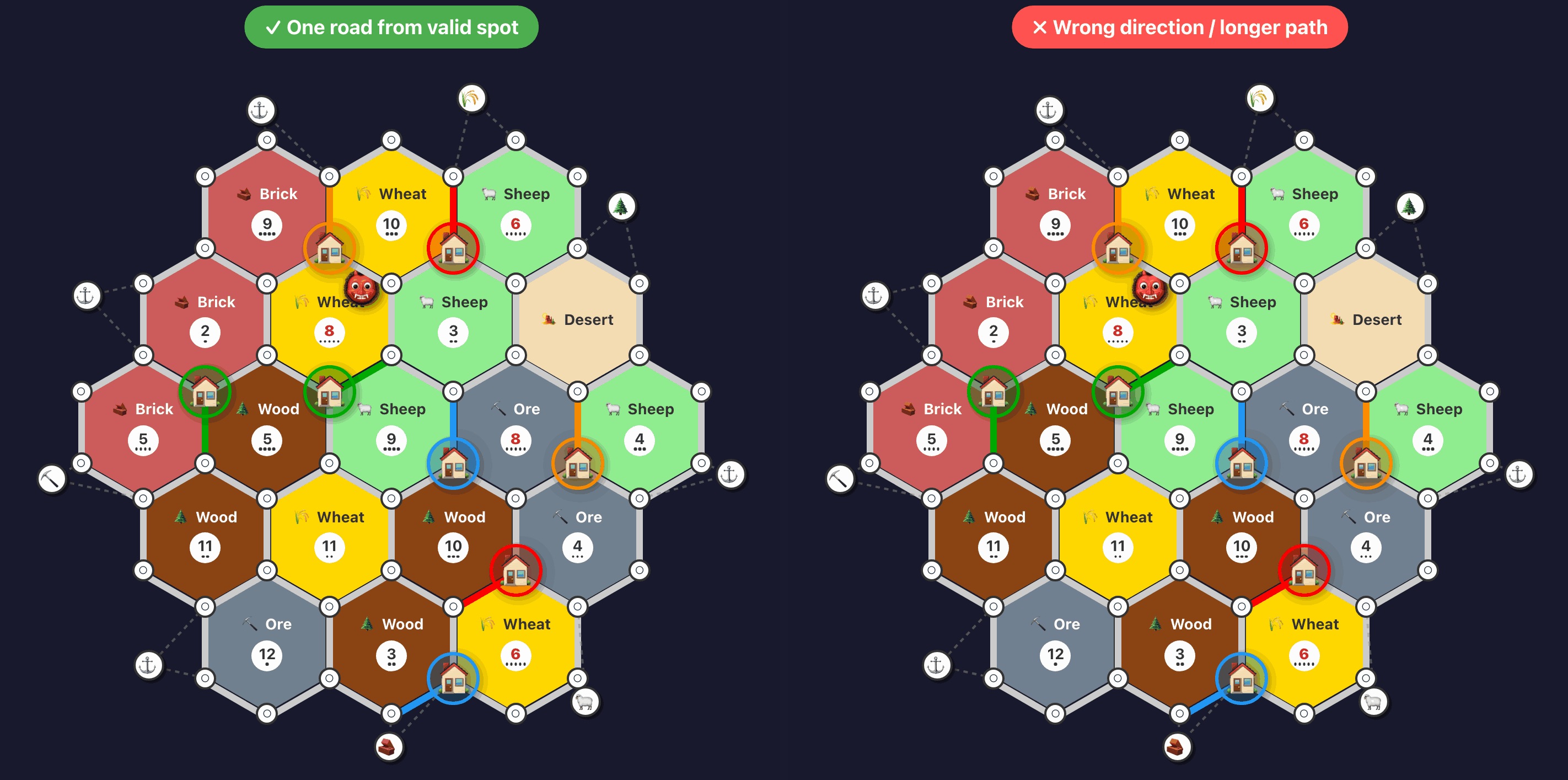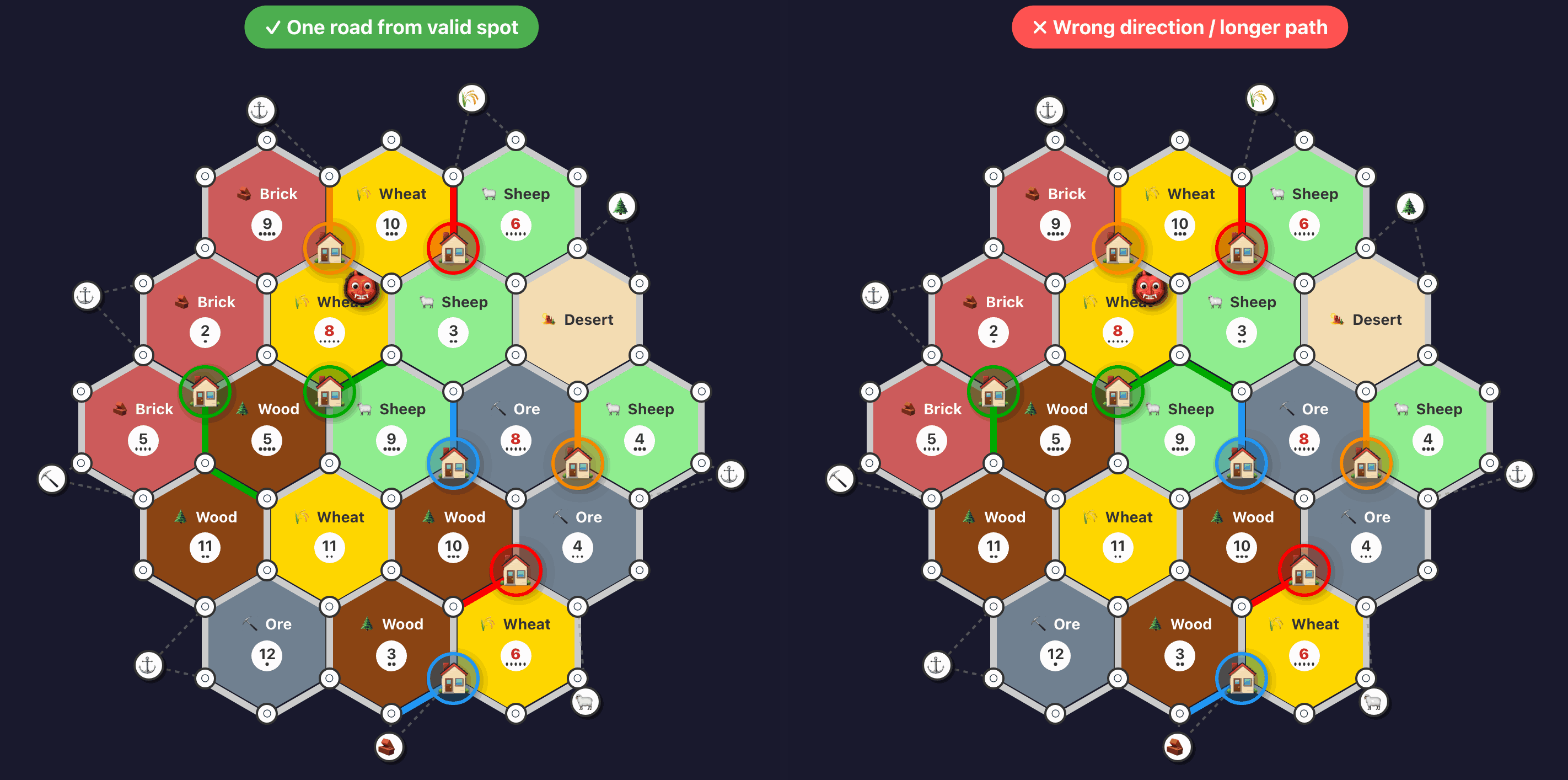
Rebuilding the clusters, I won 2/4 games3 I played against the latest agents, a 50% win rate. My average score was now 7.25 victory points. The best AI across those games averaged 8.25 victory points. Qualitatively, the agents were playing better and better, and I was having a fun time playing against the agents.
Key Technical Choices
I used gpt-5.2 without thinking because extended reasoning modes are slow, and latency matters for a real-time game interface. The retrieved guideline does the strategic lifting, so the model doesn’t need to do deep search.
I stored everything in SQLite—every game, every state transition, every decision, every piece of reasoning. This made it trivial to go back and create drills from positions I’d played days earlier.
I excluded all strategic advice from the base game rules to cleanly separate the guideline retrieval mechanism as the only source of strategy. I had tried making an initial version of the ReAct agent with generic Catan strategy in the prompt, but it tended to qualitatively make the agent worse, not better—there are a lot of potentially contradictory strategies to follow (when to build roads vs settlements vs cities, etc.), so it’s better to exclude all this information, and only include the strategic guideline relevant to the current situation.
What’s next?
I was nowhere near hitting a plateau of my system, and I hadn’t really optimized a lot of the design decisions—I doubt my vibe-coded retrieval system is optimal, the guidelines are probably overfitting I didn’t use train/val splits to generate candidate guidelines, etc. And yet, without prompt engineering or using a reasoning model, I’d turned an agent making mistakes in virtually all phases of the game—setup, trading, building settlements and cities, using development cards—into a decent agent that was actually fun to play with! Even in the modern age of LLM agents, collecting data specifying your desired model behavior goes a long way :)
VLMs aren’t ready yet :)
All designations of correct vs incorrect are my opinion, and some decisions were made for playability, such as minimizing infeasible trade requests.
Apologies for the small sample sizes. I could evaluate far more games by making the agents simply play against each other, and I will explore this in the future, but I could iterate far faster by playing a few games (in which I directly observed many mistakes), and directly patching the issues with drills.